flowchart TB
A[Corpus of documents] --> B[Document-feature matrix<br>'Bag of Words']
B --> C[Supervised<br>known categories]
B --> D[Unsupervised<br>unknown categories]
C --> E[Dictionary &<br>Sentiment]
C --> F[Wordscores &<br>Classifiers]
D --> G[Topic Models]
D --> H[Wordfish]
B --> I[Word Embeddings<br>Word2Vec, GloVe]
I -.-> J[Transformers<br>Attention mechanism]
J -.-> K[Large Language<br>Models]
style A fill:#b8d4e8,stroke:#333
style B fill:#b8d4e8,stroke:#333
style C fill:#b8d4e8,stroke:#333
style D fill:#b8d4e8,stroke:#333
style E fill:#b8d4e8,stroke:#333
style F fill:#b8d4e8,stroke:#333
style G fill:#b8d4e8,stroke:#333
style H fill:#b8d4e8,stroke:#333
style I fill:#b8d4e8,stroke:#333
style J fill:#f0e68c,stroke:#333
style K fill:#f0e68c,stroke:#333
Quantitative Text Analysis in the Age of LLMs
Seraphine F. Maerz
University of Melbourne
2026-06-17
About Me
- Senior Lecturer in Political Science (Research Methods) at Uni Melbourne; previously Goethe University Frankfurt and V-Dem Institute (Gothenburg)
- Research: democracy and democratic decline, (digital) authoritarianism, political language, comparative discourse analysis, computational methods, LLMs, co-developer of
quallmer
Website: seraphinem.github.io
Workshops on instats on AI-assisted text analysis and fine-tuning LLMs
Before LLMs: Text-as-Data
For two decades, quantitative text analysis built on the bag-of-words representation – documents reduced to feature counts.
Why LLMs Can Be Useful
| Challenge | Traditional | LLM-Based |
|---|---|---|
| Context & word order | Limited | Strong |
| Training data | Often needed | Usually not |
| Nuance, irony, ambiguity | Struggles | Better |
| Explanations | None | Can articulate reasoning |
| Reproducibility | Strong | Not 100% |
Key strength: zero-shot classification of complex, context-dependent concepts – without building a labelled training set.
Important
LLMs produce language – not truth. Validation remains essential.
Are Traditional Methods Obsolete? – No
Established text-as-data methods are still highly valuable – and often the better choice:
- Fully reproducible & transparent – a dictionary always returns the same counts
- Computationally cheap – scale to millions of documents
- Fully auditable – you can read every rule
- No external API, no privacy risk – runs entirely on your machine
- Well-understood validity for many established tasks
Prefer traditional methods when the construct is well-defined, the corpus is huge, transparency is paramount, or sensitive data cannot leave your machine.
Where Traditional Methods Still Shine
- Dictionary methods – LIWC for psychological style; VADER for social-media sentiment; populism dictionaries (Rooduijn & Pauwels 2011)
- Wordfish / Wordscores – scaling party positions from manifestos (Slapin & Proksch 2008; Laver, Benoit & Garry 2003)
- Topic models (LDA, STM) – exploring large corpora without prior categories (Roberts, Stewart & Tingley 2014)
- Supervised classifiers – fast, deterministic labelling when you already have training data
- Word embeddings – semantic change over time, conceptual similarity at scale (Rodriguez & Spirling 2022)
. . .
My advice:
Combine methods. Use traditional approaches as transparent baselines; use LLMs where context and nuance are decisive; cross-validate one against the other.
A Cross-Validation Example
Maerz & Schneider (2020), Quality & Quantity
- Corpus of 4,740 speeches by 40 heads of government in 27 countries
- Original method: dictionary-based scaling of liberal vs. illiberal rhetoric
- Finding: autocratic leaders use more illiberal language; some backsliding democracies too
The cross-validation question:
- Can an LLM reproduce the dictionary-based scores?
- Where do the two methods agree – and where do they diverge?
- A well-established traditional baseline is highly valuable for an LLM workflow.
![]()
An R package for LLM-assisted qualitative coding with built-in transparency, validation, and audit trails. Works with text, images, PDFs, audio; supports open and closed LLMs.
| Step | Function | Purpose |
|---|---|---|
| 1 | qlm_codebook() |
Define your coding scheme |
| 2 | qlm_code() |
Apply codebook to texts |
| 3 | qlm_replicate() |
Test robustness across models / settings |
| 4 | qlm_compare(), qlm_validate() |
Reliability & validity |
| 5 | qlm_trail() |
Audit documentation |
Install with install.packages("quallmer") – co-developed with Kenneth Benoit. Full docs: quallmer.github.io/quallmer.
Step 1: Define the Codebook
library(quallmer)
codebook_ideology <- qlm_codebook(
name = "Liberal-illiberal rhetoric",
instructions = "Analyze the rhetorical style of this political speech.
ILLIBERAL rhetoric (negative scores): nationalism, paternalism, traditionalism.
LIBERAL rhetoric (positive scores): individual rights, tolerance, civil liberties.
Score 0 = neutral/mixed.",
schema = type_object(
score = type_integer("Score from -10 (illiberal) to +10 (liberal)"),
explanation = type_string("Brief explanation of the score")
)
)The schema defines the structured output – here, the LLM returns both a score and an explanation. The codebook mirrors the conceptual categories of the original dictionary.
Schema Options
The schema defines what the LLM returns:
| Type | Use for | Example |
|---|---|---|
type_integer() |
Fixed categories | c("pos", "neg", "neutral") |
type_string() |
Text/explanations | "Brief explanation" |
type_number() |
Number scores | -10 to +10 |
type_boolean() |
Yes/no questions | TRUE/FALSE |
type_array() |
Lists of items | Persons, relationships, things, etc. |
Tip
The schema is flexible – you can ask for multiple fields and nest objects for more complex outputs. Think carefully about what you want to get back from the LLM, the schema will guide the response format and content.
Step 2: Code the Data
Returns a qlm_coded object with:
- Coding results (score, explanation)
- Full metadata (timestamps, model identifiers, codebook used)
Step 3: Replicate Across Models
Provenance chains link replicated results to their parent analyses – a first, internal cross-validation across LLMs.
Step 4: Cross-Validate Against the Dictionary
Metrics available:
- Krippendorff’s alpha, Cohen’s kappa, Fleiss’ kappa
- Accuracy, precision, recall, F1 scores
- Correlation and RMSE for interval-level outputs
For manual review and spot-checking, use the companion quallmer.app Shiny application.
Step 5: Audit Trail
Following Lincoln & Guba (1985), the audit trail includes:
- Instrument development (codebook definition)
- Process notes & decisions (model parameters, timestamps)
- Parent-child relationships across analyses
- Complete replication code
Results: LLM vs. Dictionary Scores
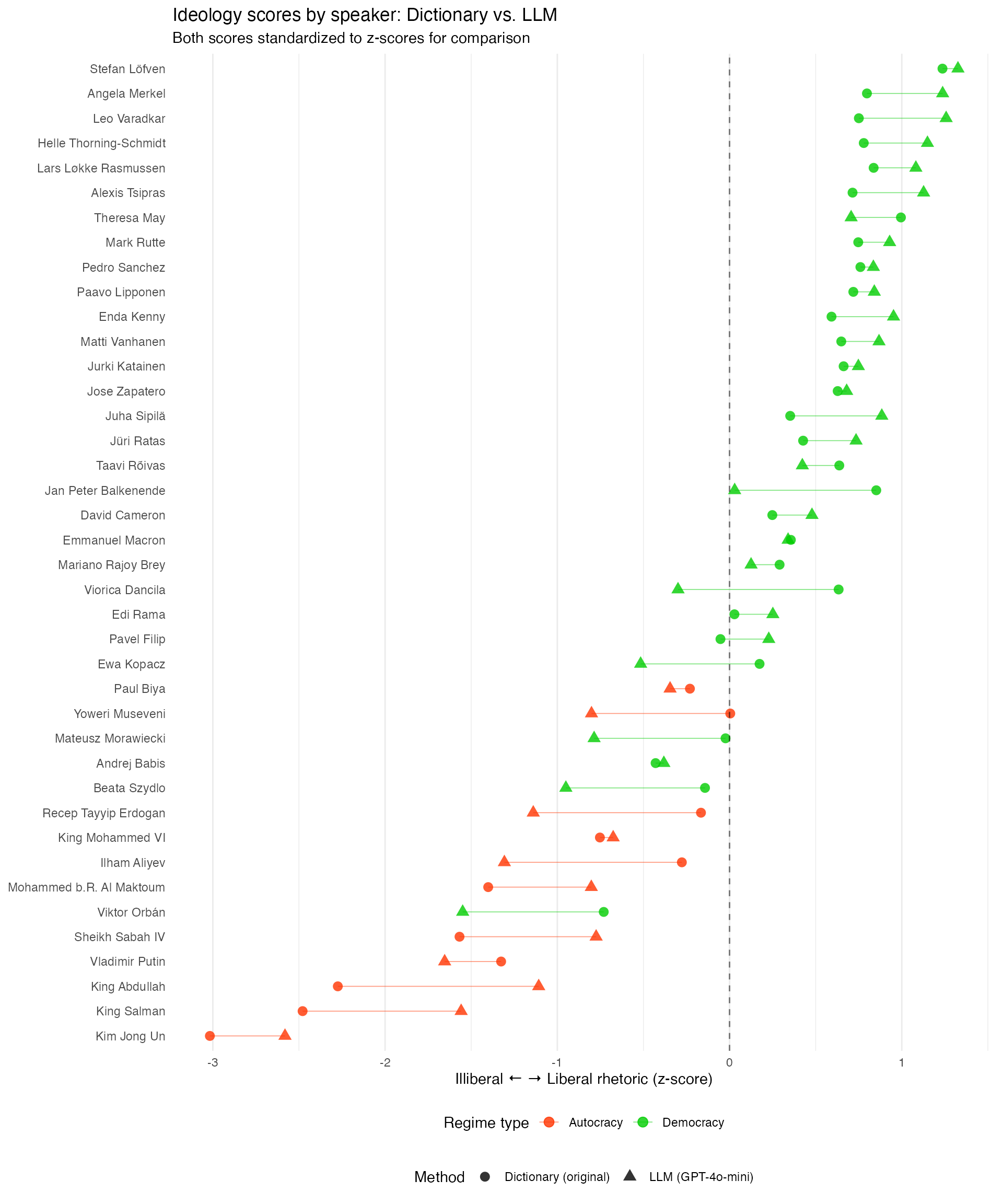
Cross-validation outcome:
- LLM scores correlate strongly with the dictionary baseline
- The traditional method is vindicated – the LLM is a valid alternative
- LLM adds: per-document explanations and sensitivity to context
- Dictionary keeps: full transparency, zero cost, perfect reproducibility